高精度な日本語マルチモーダル大規模言語モデルの構築にむけたデータセットの検討 (NLP2025)
田中 幹大, 朱 佩菲, 横尾 修平 (LINEヤフー株式会社) [paper]
このページではNLPの論文内容に加え、新しく日本語MLLMの評価ベンチマークとして提案するJIC-VQAについても紹介する。
概要
近年、大規模言語モデル (LLM) に視覚情報を統合した、マルチモーダル大規模言語モデル(MLLM)が注目を集めており、その応用範囲は急速に拡大している。しかし、日本ドメインに特化したMLLM を作る上で、英語のデータに比べて公開データが少ない課題がある。本研究では、高精度な日本語MLLMを構築するためのデータセットの作成方法について検討し、実験を行った。構築したモデルは、日本ドメインの画像理解を問うベンチマークにおいて、他のモデルよりも優位な結果を示し、その有効性を実証した。
また、日本語MLLMを作るにあたり、日本ドメイン画像の認識能力は最も基礎的で重要な能力の一つである。しかし、従来のベンチマークではこの点に焦点をおいた評価が行いづらい課題があった。そこで、日本ドメイン画像の認識能力を問うベンチマーク: JIC-VQAを提案した。提案するベンチマークにより、日本語MLLMにおいても日本ドメインに強い画像エンコーダーを作っていくことが重要であることを示した。
実験結果
提案モデルは、日本ドメインの画像を扱うHeron-BenchとJA-VLM-Benchにおいて既存手法を上回る性能を達成した。 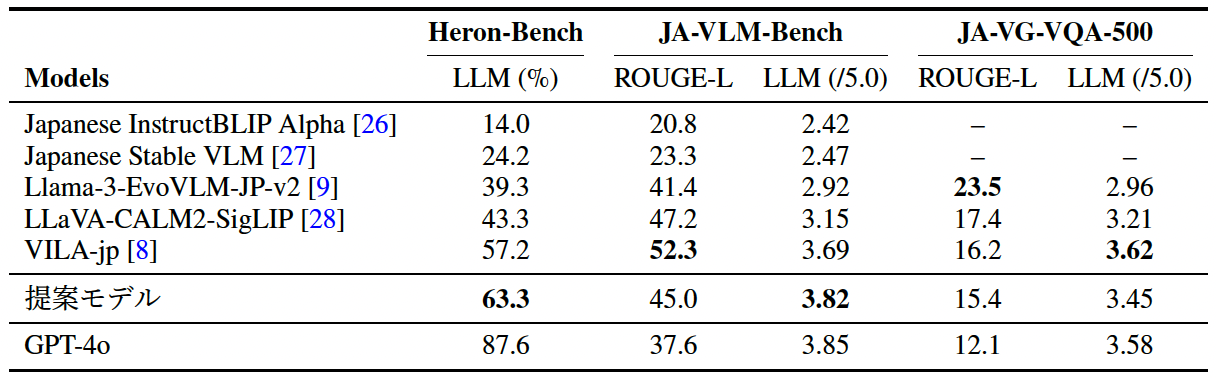
定性的結果例を以下に示す。提案モデルは左のHeron-Benchの例では日本固有の「風神雷神」を認識しており、右のJA-VLM-Benchの例では2つの交通標識を正しく認識していることが分かる。 
本研究ではCALM3-22Bを用いてMLLMを構築した。本研究で構築したデータセットの有用性を確認するために、VILA-jpと同様llm-jp-3-13b-instructを用いた実験を行った。
llm-jp-3-13b-instructを用いた時は、提案データセットに対して適切なフィルタリングを行うことでVILA-jpを上回る性能を得た(表上から3番目)。ここで、フィルタリングは作成したデータの中で、解答文に疑問文を含むものを除く処理を行った。
| Models | Heron-Bench LLM Average (%) | JA-VLM-Bench LLM (/5.0) |
|---|---|---|
| VILA-jp (SigLIP + llm-jp-3-13b-instruct) | 57.2 | 3.69 |
| (提案データ) SigLIP + llm-jp-3-13b-instruct | 56.6 | 3.62 |
| (提案データ+filtering) SigLIP + llm-jp-3-13b-instruct | 60.4 | 3.7 |
JIC-VQAベンチマークの作成
日本語MLLMを作る上で、日本ドメインの画像を認識できるかは最も基礎的で重要な能力の一つである。これまで日本ドメイン画像を用いて、Heron-BenchやJA-VLM-Benchに加えて、JMMMUといったベンチマークが提案されてきた。しかしこれらのベンチマークでは、知識を問うものなどのLLMの能力が重要となる質問が多く含まれているため、日本ドメインの画像認識に焦点を置いた基礎的な能力を評価できない課題があった。
そこで、Recruit社が日本語CLIPの評価のために公開したjapanese-image-classification-evaluation-datasetを用いて4択式の7,654件の質問を付与して日本語MLLMの評価用に拡張した、Japanese-Image-Classification-VQA(JIC-VQA)と呼ぶベンチマークによる評価を提案する。4つの選択肢のうち誤りの回答は、正解と最も類似しているクラスをクラス名の候補からLLMによって選択して用意した。
提案するJIC-VQAベンチマークは、元のデータセットと同じで、jaflower30(日本の花30種)・jafood101(日本の食材、料理101種)・ jalandmark10(日本のランドマーク10種)・jafacility20(日本の施設20種)から構成される。
ベンチマークの例を以下に示す。 
日本語MLLMの評価に一般的に用いられるベンチマークとの比較を以下の表に示す。提案するJIC-VQAは日本ドメインの画像の常識的なレベルの理解を問う、大きなベンチマークとなっている。
| ベンチマーク | 画像ドメイン | 質問数 | レベル | 評価方法 |
|---|---|---|---|---|
| Heron-Bench | 日本 | 102 | 常識 | LLM |
| JA-VLM-Bench | 日本 | 60 | 常識 | 自動評価 or LLM |
| JA-VG-VQA-500 | 海外 | 4,000 | 常識 | 自動評価 or LLM |
| JMMMU | 日本 | 1,320 | 専門的 | 正解率 |
| JIC-VQA (提案) | 日本 | 7,654 | 常識 | 正解率 |
評価結果を以下の表に示す。日本語版CLIPとは、日本ドメインに特化したCLIPであるclip-japanese-baseをベースとし、ViT-L/14@336pxを用いて開発したモデルである。MLLMの画像エンコーダーとして日本語版CLIPを用いたモデルは、海外ドメインで主に訓練されているSigLIPを用いたモデルの性能を大きく上回り、特に食べ物やランドマークの認識で差がついた。
公開されているMLLMには、日本ドメインに特化させていないが高い日本語能力を持つものがある。表には代表的なモデルとして、Qwen2-VL-7B-InstructとInternVL2-8Bの結果も示している。Qwen2-VL-7B-Instructは高い認識能力を示したが、日本の食べ物の認識能力は弱く、特定のカテゴリの認識には弱いことが伺える。
| モデル | jaflower30 | jafood101 | jalandmark10 | jafacility20 | 平均 |
|---|---|---|---|---|---|
| LLaVA-CALM2-SigLIP | 0.61 | 0.55 | 0.42 | 0.77 | 0.59 |
| VILA-jp (SigLIP + llm-jp-3-13b-instruct) | 0.91 | 0.76 | 0.74 | 0.89 | 0.83 |
| Qwen2-VL-7B-Instruct | 0.91 | 0.79 | 0.92 | 0.93 | 0.87 |
| InternVL2-8B | 0.48 | 0.63 | 0.71 | 0.81 | 0.66 |
| (提案データ) SigLIP + CALM3-22B | 0.92 | 0.84 | 0.79 | 0.86 | 0.85 |
| (提案データ) 日本語版CLIP + CALM3-22B | 0.95 | 0.91 | 0.89 | 0.93 | 0.92 |
定性的な結果を以下の図に示す。海外ドメインを中心として学習されたSigLIPを画像エンコーダーを用いると、豊富な日本ドメインの知識を持つLLMと合わせてMLLMを学習しても基本的な日本ドメインの画像認識に失敗することがある事が分かる。これらの結果からも、日本ドメインに強力な画像エンコーダーの構築が重要であることが分かる。
